This is a slight variation of a theme, I was already blogging about some time ago. But I recently had a discussion with a colleague and thought it would be worthwhile to share my notes here. So what might go wrong if you control for post-treatment variables in your statistical model? From economists you might hear something like “a post-treatment variable is endogenous, and you shouldn’t control for endogenous variables”. But that’s too vague of an answer. Take for example the following setting, which is inspired by my own research.

There is a large literature documenting that firms which are predominantly owned by single families often invest less in innovation and R&D. Reasons for this are that family owners often want to keep tight control over the company, which leads to conservatism in their decision-making and a reluctance to involve outside investors. This makes it harder for them to finance risky and expensive R&D projects. Obviously, in the long-run, this will have an effect on performance, if family firms invest too little in new product development and optimizing their production processes.
Now imagine I want to analyze the relationship between family ownership and firm performance, but I’m not really interested in R&D expenditures. Maybe I want to investigate another phenomenon related to family owners and the innovation aspect is already too well researched to care for it anymore. At the same time though I know that R&D expenditures are an important factor and I should better account for it. So if the graph above is indeed the correct model, I could include R&D ependitures in my regression to hold them constant across firms. Any effect of innovation spending on performance would then be eliminated and I could focus on whatever else I’m interested in. This works even though R&D expenditures are an endogenous, post-treatment variable in the model (you can see this by the arrow that points into it).
So far no problem. But the situation changes dramatically if we add an unobserved confounder.
 Now R&D expenditures become what we call a collider variable, because two arrows, one emitted from family ownership and the other from U, meet in it. Colliders are a tricky business because they open up biasing paths if we control for them (here: family ownership
Now R&D expenditures become what we call a collider variable, because two arrows, one emitted from family ownership and the other from U, meet in it. Colliders are a tricky business because they open up biasing paths if we control for them (here: family ownership 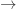
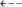

Unfortunately, it’s quite likely that there are unobserved variables that affect both R&D expenditures and firm performance, such as general management quality or a particularly well-trained workforce. Therefore, collider bias is a huge risk when controlling for post-treatment variables.
Sometimes people operate under the vague notion that if they include post-treatment variables in a regression they could get at a causal effect “net of this variable”. Or put differently, they think they could say something about the different causal mechanisms that are at play. This view is tricky, if not mistaken! Because if there are unobserved confounders between the outcome and the intermediate variable, like in the example above, it’s impossible to keep the two causal mechanisms apart. That’s exactly why mediation analysis is so hard. Kosuke Imai and coauthors have developed a sensitivity analysis, which allows you to check whether your mediation analysis remains robust to a mediator-outcome-correlation. If you’re interested in mediation analysis, you can also check out this previous post of mine.
In any case, stay safe and watch out for collider bias!

Firstly, thank you for your insightful blogs!
1) Under unconfoundedness assumption of mediator, would both ,”just controlling for mediator” and mediation analysis, give the same answer for the direct effect (in linear setting) ?
2) If mediation analysis also requires unconfoundedness of mediator variable then what is the advantage over conditioning?
Thanks!
LikeLike
Hi Mrunal – Thanks! Regarding your questions:
1) With unconfoundedness of the mediator and effect homogeneity in a linear setting, the two are equivalent (i.e., it’s the standard Baron & Kenny 1986 procedure for mediation analysis). However, these are very strong assumptions, of course, and should be defended more carefully than typical papers in the field do.
2) The traditional Barion & Kenny (1986) is actually nothing more than conditioning on the mediator to back out the direct effect. The problem is that this doesn’t hold in more general settings when counterfactuals differ across individuals, as it is nicely explained here: https://ftp.cs.ucla.edu/pub/stat_ser/r379.pdf
LikeLike
Thank you!
LikeLike